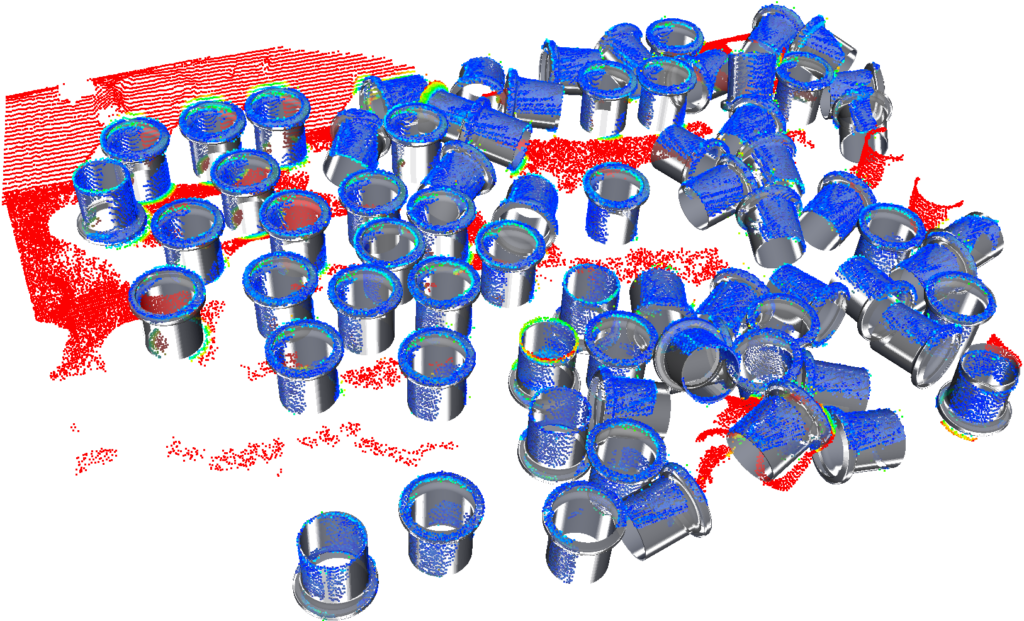
GUICANDELOR now comes with a graphical user interface to test and automatically configure the matching algorithm. Give it a try!
GUICANDELOR now comes with a graphical user interface to test and automatically configure the matching algorithm. Give it a try!





![]() WHO WE ARE
WHO WE ARE
The PROFACTOR Group is based in Steyr, Austria. We develop new technologies, solutions, and products in the areas of production, nano technology, and energy.
![]() WHAT WE DO
WHAT WE DO
The most important for us is to enable innovation by leveraging the breakthrough of 3D application with the easy-to-use-principle of CANDELOR and ReconstructMe.
![]() WHAT IS CANDELOR
WHAT IS CANDELOR
CANDELOR is a solution for 3D scene interpretation. It contains a highly scalable, robust, and flexible 3D object localization algorithm.
![]() HOW TO GET IT
HOW TO GET IT
You can download a free full evaluation version of CANDELOR. Pricing models and evaluation version are available here.